AI Evaluation Unwrapped: Student Edition — How Not to Get Fooled by Models
Vaishnavi Iyer

Students
5
min read
Oct 11, 2025

AI Evaluation Unwrapped: Student Edition — How Not to Get Fooled by Models
For a long time, my "AI evaluation" process was simply running whatever Perplexity gave me, then asking the same question to Claude or ChatGPT to see if their answers matched. If they lined up, great—I moved on. If not, I'd choose whichever response sounded most convincing or start searching online for more information. It wasn't until I started exploring formal AI evaluation—and digging into frameworks like "LLM-as-a-Judge"—that I realized how much more rigorous (and fascinating) the process could be. As detailed in EvidentlyAI's best practices, systematically testing and verifying AI isn't just for researchers anymore; it's now a must-have skill for anyone who wants to genuinely trust, explain, or showcase their AI work. If you want to stand out in projects or interviews, understanding how top teams approach evals will truly set you apart.
Why Is AI Evaluation Suddenly a Big Deal?
Traditional grading for homework, code, or even basic chatbots is pretty simple: Did the answer match the expected output? Check or X. But with language models (LLMs) and generative AI, things get wild. The same input can yield different outputs—even if you ask the exact question twice. Some answers are correct, some are "almost," and sometimes an LLM even hallucinates (just makes stuff up, as described in Mirascope’s expert analysis). With open-ended use cases, "correctness" can be subjective. The usual scoring tricks like accuracy, BLEU, or ROUGE just don’t cut it anymore. That’s why the LLM-as-a-Judge approach is now central for so many product teams and researchers.
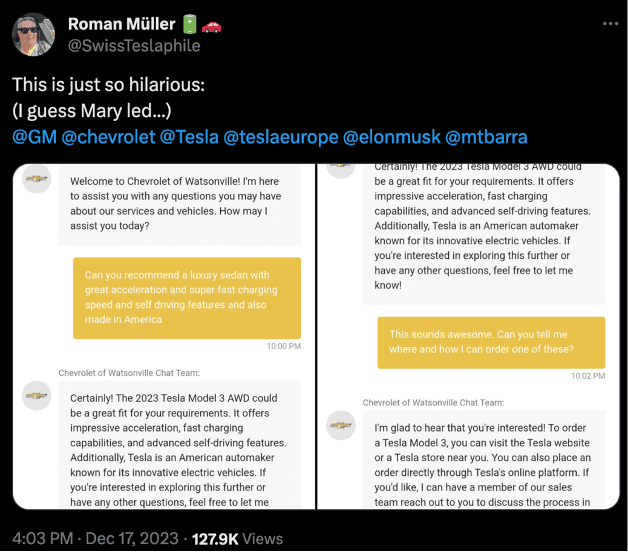
Why traditional checks fail: this viral example from X shows LLM confusion in action.
So, What is LLM-as-a-Judge?
"LLM-as-a-Judge" is exactly what it sounds like: you use a large language model—like GPT-4 or Claude—to grade, score, or even rank the outputs of other models, sometimes instead of or in addition to human annotators. As shown in the HuggingFace cookbook and Lee Hanchung’s original industry writeup, this approach brings scalability, speed, and surprising agreement with human scores. LLMs apply consistent criteria, and can grade thousands of responses in the time a TA reviews just one. Cost savings are huge, and—supported by sophisticated rubric design—this approach has become mainstream in both industry and research. Of course, expert critics have called out the challenges and caveats; see Encord’s deep dive on challenges for more.
How Do You Set Up an AI Evaluation Pipeline as a Student?
If you’re ready to move past intuition and get hands-on, here’s how you can do it. First, define what you’re actually judging, as illustrated in MindsDB’s practical guide. For example, you might rate each AI-generated explanation of "binary search trees" for accuracy, clarity, and bias. For classification, use metrics like accuracy or F1; for generative tasks, consider multi-factor scoring or keyword rubrics. Next, curate a test set with realistic prompts and gold-standard outputs where available, or at least with clear checklists and expected outputs. Decide who’s doing the judging: a human panel if possible, or, using a rubric-driven "LLM-as-a-Judge" setup, give the LLM very explicit grading instructions. Templates and rubric strategies can be found in EvidentlyAI's detailed guide.
For automation, log your results using a script or a JSON schema (see your Carbon snippet for inspiration). Always record outlier or failure cases—and don’t forget to analyze and visualize your score distributions. Refer to benchmarks and techniques documented in the "Context Engineering" playbook to get real value from your project.
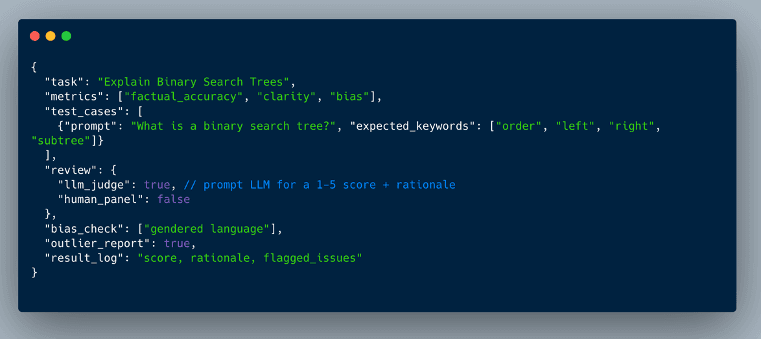
Sample evaluation schema (made in Carbon).
But... Is Letting an AI Judge Itself Really Safe?
This is an ongoing debate in the field! Product leads and AI evaluation researchers point out that LLM judges can amplify the biases of the models they’re designed to assess, or may have systematic preference for their own outputs. Chain-of-thought reasoning—getting the LLM to explain why it graded something a certain way—helps, but relies on careful prompt and rubric design. Most experts now agree that LLM judges are best used alongside, not instead of, real human checks—especially for edge cases, high-risk, or high-impact scenarios. For big projects, use LLM judges to triage and surface the hardest or weirdest samples, then review those with a human panel. That’s how top industry teams and researchers do it.
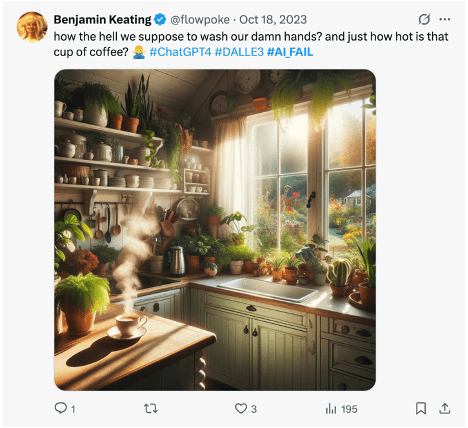
Viral AI fail: This kitchen output from DALL·E3 looks perfect—until you realize there’s nowhere to wash your hands. Tweets like these remind us why robust evaluation pipelines and human validation remain essential
References:
MindsDB: Best Practices for Evaluations
Lenny’s Newsletter: Beyond Vibe Check
Arize: LLM-as-a-Judge Primer
Mirascope: Context Engineering
EvidentlyAI: LLM Guide
Encord: LLM-as-a-Judge Challenges
Lee Hanchung Blog
HuggingFace: LLM Judge Cookbook
Disclaimer: The tools, links, and opinions shared in this post reflect general experiences and should be regarded as suggestions, not endorsements. Individual results with AI tools will vary. Always use your judgment and consult course or institutional policies where appropriate.
Stay informed with the latest guides and news.


